Introduction: What is Onion Architecture?
The problel with tradional architechture used in ASP .Net was tight coupling and separation of concerns.
Onion Architecture was introduced by Jeffrey Palermo to provide a better way to build applications in perspective of better testability, maintainability, and dependability.
Onion Architecture addresses the challenges faced with 3-tier and n-tier architectures, and to provide a solution for common problems. Onion architecture layers interact to each other by using the Interfaces.
Principles
Onion Architecture is based on the inversion of control principle.
Onion Architecture is comprised of multiple concentric layers interfacing each other towards the core that represents the domain. The architecture does not depend on the data layer as in classic multi-tier architectures, but on the actual domain models.
Problem and Solution
As per traditional architecture, the UI layer interacts to business logic, and business logic talks to the data layer, and all the layers are mixed up and depend heavily on each other. In 3-tier and n-tier architectures, none of the layers are independent; this fact raises a separation of concerns. Such systems are very hard to understand and maintain. The drawback of this traditional architecture is unnecessary coupling.

Onion Architecture solved these problem by defining layers from the core to the Infrastructure. It applies the fundamental rule by moving all coupling towards the center. This architecture is undoubtedly biased toward object-oriented programming, and it puts objects before all others. At the center of Onion Architecture is the domain model, which represents the business and behavior objects. Around the domain layer are other layers, with more behaviors.
Layers of Onion Architecture
Onion Architecture uses the concept of layers, but they are different from 3-tier and n-tier architecture layers. Let's see what each of these layers represents and should contain.
Domain Layer
At the center part of the Onion Architecture, the domain layer exists; this layer represents the business and behavior objects. The idea is to have all of your domain objects at this core. It holds all application domain objects. Besides the domain objects, you also could have domain interfaces. These domain entities don't have any dependencies. Domain objects are also flat as they should be, without any heavy code or dependencies.
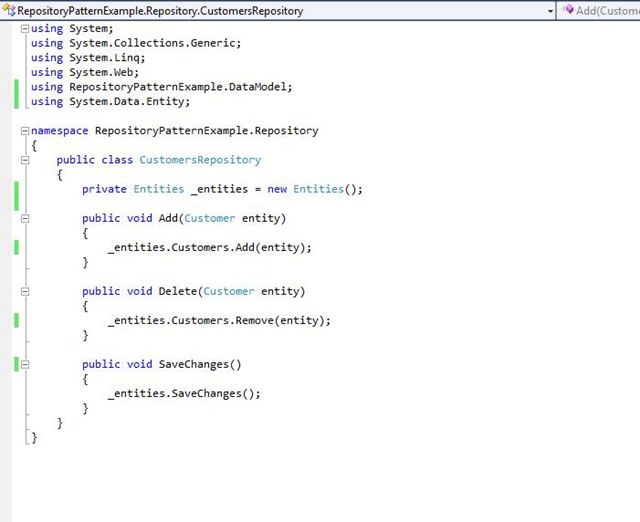
Repository Layer
This layer creates an abstraction between the domain entities and business logic of an application. In this layer, we typically add interfaces that provide object saving and retrieving behavior typically by involving a database. This layer consists of the data access pattern, which is a more loosely coupled approach to data access. We also create a generic repository, and add queries to retrieve data from the source, map the data from data source to a business entity, and persist changes in the business entity to the data source.
Services Layer
The Service layer holds interfaces with common operations, such as Add, Save, Edit, and Delete. Also, this layer is used to communicate between the UI layer and repository layer. The Service layer also could hold business logic for an entity. In this layer, service interfaces are kept separate from its implementation, keeping loose coupling and separation of concerns in mind.
UI Layer
It's the outer-most layer, and keeps peripheral concerns like UI and tests. For a Web application, it represents the Web API or Unit Test project. This layer has an implementation of the dependency injection principle so that the application builds a loosely coupled structure and can communicate to the internal layer via interfaces.
Implementation of Onion Architecture
No direction is provided by the Onion Architecture guidelines about how the layers should be implemented. The architect should decide the implementation and is free to choose whatever level of class, package, module, or whatever else is required to add in the solution.
Benefits and Drawbacks of Onion Architecture
Following are the benefits of implementing Onion Architecture:
Onion Architecture layers are connected through interfaces. Implantations are provided during run time.
Application architecture is built on top of a domain model.
All external dependency, like database access and service calls, are represented in external layers.
No dependencies of the Internal layer with external layers.
Couplings are towards the center.
Flexible and sustainable and portable architecture.
No need to create common and shared projects.
Can be quickly tested because the application core does not depend on anything.
A few drawbacks of Onion Architecture as follows:
Not easy to understand for beginners, learning curve involved. Architects mostly mess up splitting responsibilities between layers.
Heavily used interfaces
Conclusion
Onion Architecture is widely accepted in the industry. It's very powerful and closely connected to two other architectural styles—Layered and Hexagonal.
The internal layers never depend on external layer. The code that may have changed should be part of an external layer.
Source :
https://www.codeguru.com/csharp/csharp/cs_misc/designtechniques/understanding-onion-architecture.html
https://blog.thedigitalgroup.com/understanding-onion-architecture