Let’s create a sample Employee table and insert a few records in it.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | CREATE TABLE Employee ( [ID] INT identity(1,1), [FirstName] Varchar(100), [LastName] Varchar(100), [Country] Varchar(100), ) GO Insert into Employee ([FirstName],[LastName],[Country] )values('Raj','Gupta','India'), ('Raj','Gupta','India'), ('Mohan','Kumar','USA'), ('James','Barry','UK'), ('James','Barry','UK'), ('James','Barry','UK') |
In the table, we have a few duplicate records, and we need to remove them.
SQL delete duplicate Rows using Group By and having clause
In this method, we use the SQL GROUP BY clause to identify the duplicate rows. The Group By clause groups data as per the defined columns and we can use the COUNT function to check the occurrence of a row.
For example, execute the following query, and we get those records having occurrence greater than 1 in the Employee table.
1 2 3 4 5 6 7 8 9 | SELECT [FirstName], [LastName], [Country], COUNT(*) AS CNT FROM [SampleDB].[dbo].[Employee] GROUP BY [FirstName], [LastName], [Country] HAVING COUNT(*) > 1; |
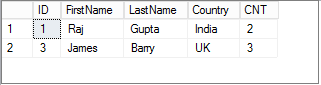
In the output above, we have two duplicate records with ID 1 and 3.
- Emp ID 1 has two occurrences in the Employee table
- Emp ID 3 has three occurrences in the Employee table
We require to keep a single row and remove the duplicate rows. We need to remove only duplicate rows from the table. For example, the EmpID 1 appears two times in the table. We want to remove only one occurrence of it.
We use the SQL MAX function to calculate the max id of each data row.
1 2 3 4 5 6 7 8 9 10 | SELECT * FROM [SampleDB].[dbo].[Employee] WHERE ID NOT IN ( SELECT MAX(ID) FROM [SampleDB].[dbo].[Employee] GROUP BY [FirstName], [LastName], [Country] ); |
In the following screenshot, we can see that the above Select statement excludes the Max id of each duplicate row and we get only the minimum ID value.
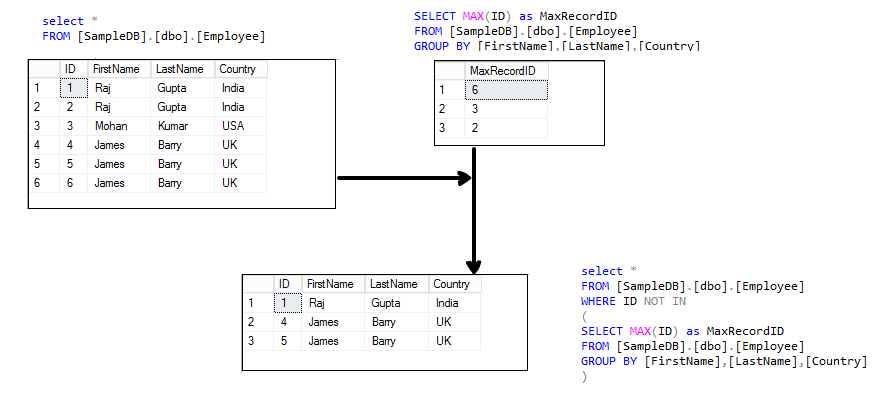 To remove this data, replace the first Select with the SQL delete statement as per the following query.
To remove this data, replace the first Select with the SQL delete statement as per the following query.
1 2 3 4 5 6 7 8 9 | DELETE FROM [SampleDB].[dbo].[Employee] WHERE ID NOT IN ( SELECT MAX(ID) AS MaxRecordID FROM [SampleDB].[dbo].[Employee] GROUP BY [FirstName], [LastName], [Country] ); |
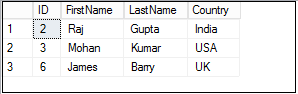
Once you execute the delete statement, perform a select on an Employee table, and we get the following records that do not contain duplicate rows.
No comments:
Post a Comment